
I joined this project as a UX designer, but quickly realized the AI engine was way behind. So I dove in, built the ML/NLP stack from scratch, and scaled the whole thing to web scale. If you want to see how to go from zero to 250M+ docs and real LLM-powered search, this is it.
Challenge
Transform a small, manually curated knowledge base into a web-scale platform capable of identifying novel sustainable innovations by processing vast volumes of unstructured text data. Evolve from basic search functionality to sophisticated AI-driven insights and discovery.
My Role & Evolution
I joined the team in 2018 as a UX designer. But after less than a year, I completed all the UX research and design work, and discovered that the AI engine was far behind what the UI promised. This challenge excited me so much that I naturally transitioned to working on what I’m truly passionate about: AI and NLP.
At the time:
- Our database contained only a few thousand manually curated innovations
- Almost no ML systems were in production
- No automated data pipelines existed
- Search was mostly keyword and rule-based
- The system wasn’t optimized to find solutions to user problems as intended
Key Contributions
Neural Semantic Search Transformation
First, I proposed a shift to neural semantic search:
- Ran an annotation project that resulted in a manually labeled innovation search dataset
- Trained and tested hundreds of different retrieval and re-ranking models
- Implemented vector search solutions
- Helped deploy the best models into production
- The semantic search system I developed is still running in production today
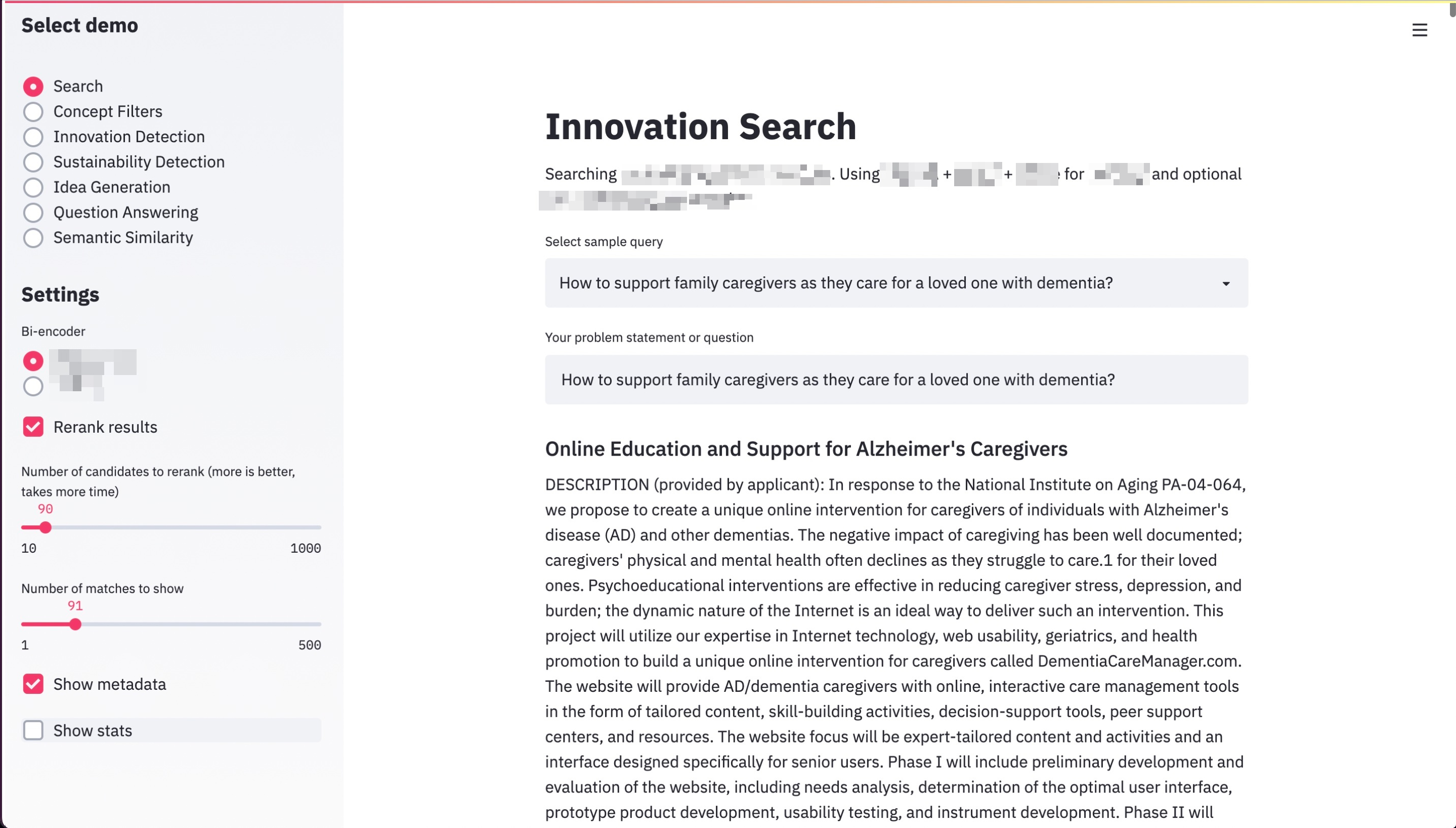 Figure 1: One of my first semantic search demos (2019), showcasing contextual document retrieval
Figure 1: One of my first semantic search demos (2019), showcasing contextual document retrieval
Web-Scale Data Pipeline
I championed the idea that we needed to exponentially grow our database:
- Proposed scaling from thousands to hundreds of millions of entries by processing web content
- Advocated for importing research papers, patents, and news
- Trained custom ML models for domain classification, page classification, and entity extraction
- Built a pipeline that could mine the internet and import potential innovative solutions
- Scaled the database to over 250 million documents in production
Early LLM Innovation (2019)
Shortly after GPT-2 was released in 2019:
- Fine-tuned it as an idea generator for creative problem solving
- Deployed it as a Slack bot (later rebuilt by colleagues for MS Teams)
- To my knowledge, this was one of the earliest documented enterprise uses of a language model for automated ideation
- This early LLM application sparked user interest and excited investors
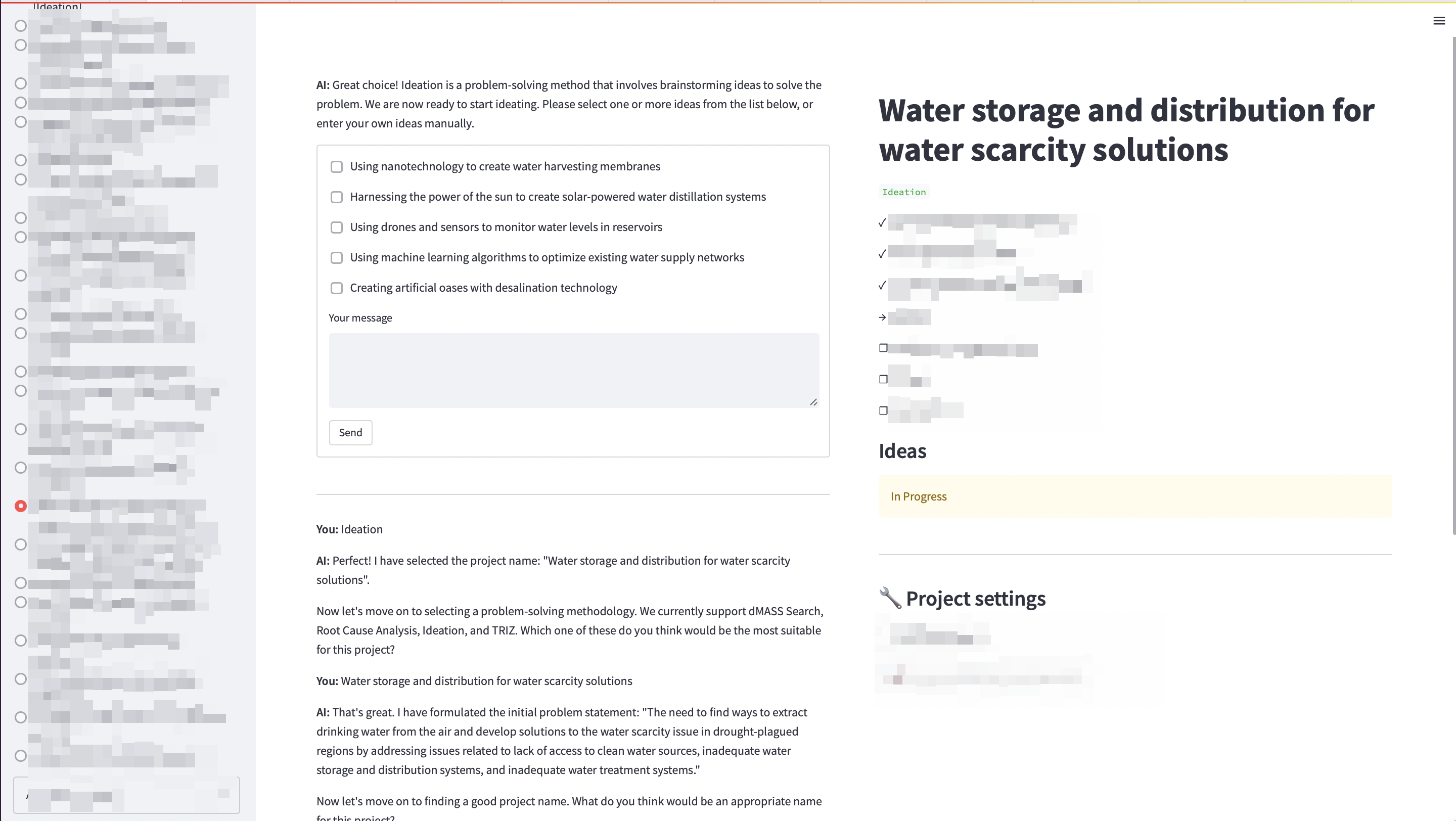 Figure 2: Human-AI collaborative ideation platform for generating novel innovation concepts
Figure 2: Human-AI collaborative ideation platform for generating novel innovation concepts
Advanced NLP Systems
I designed and developed numerous custom ML systems that improved the quality of our data:
- Custom NER & Knowledge Graph: Created entity extraction and linking pipeline
- Extracted named entities and relations
- Linked them to Wikidata and other knowledge bases
- Built a proprietary knowledge base for emerging innovations not yet in public sources
- Giving users a critical time advantage in discovering emerging technologies
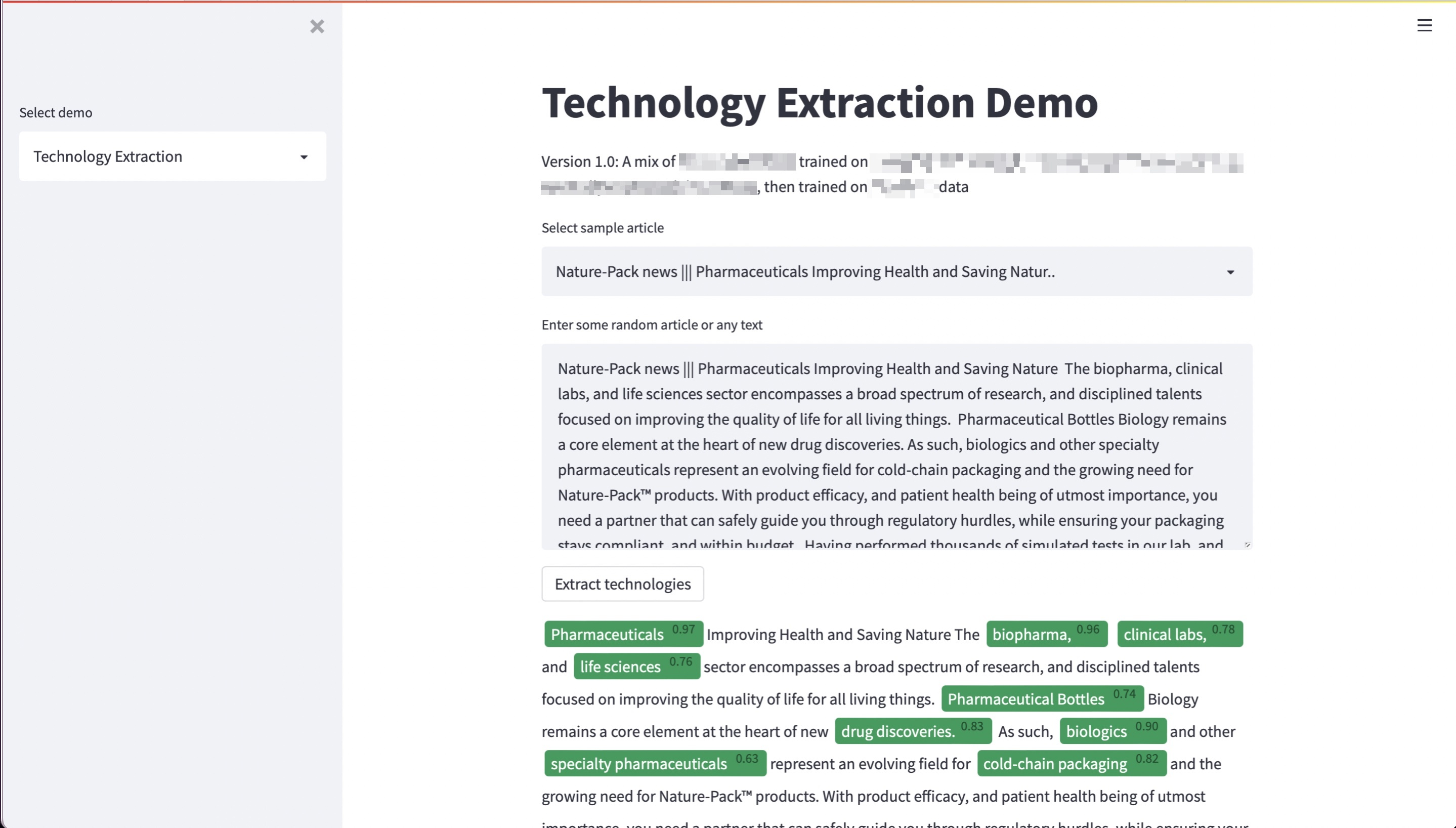 Figure 3: Custom-trained NER model identifying and extracting emerging technologies from unstructured text
Figure 3: Custom-trained NER model identifying and extracting emerging technologies from unstructured text
- Pioneering LLM Techniques:
- Started using LLMs for knowledge extraction and data augmentation years ahead of mainstream adoption
- Designed prompting methods similar to what is now called Self-Ask, Chain-of-Thought, and Scratchpads years ahead of mainstream adoption
- Created advanced dialog systems incorporating background search, source citation, and goal completion
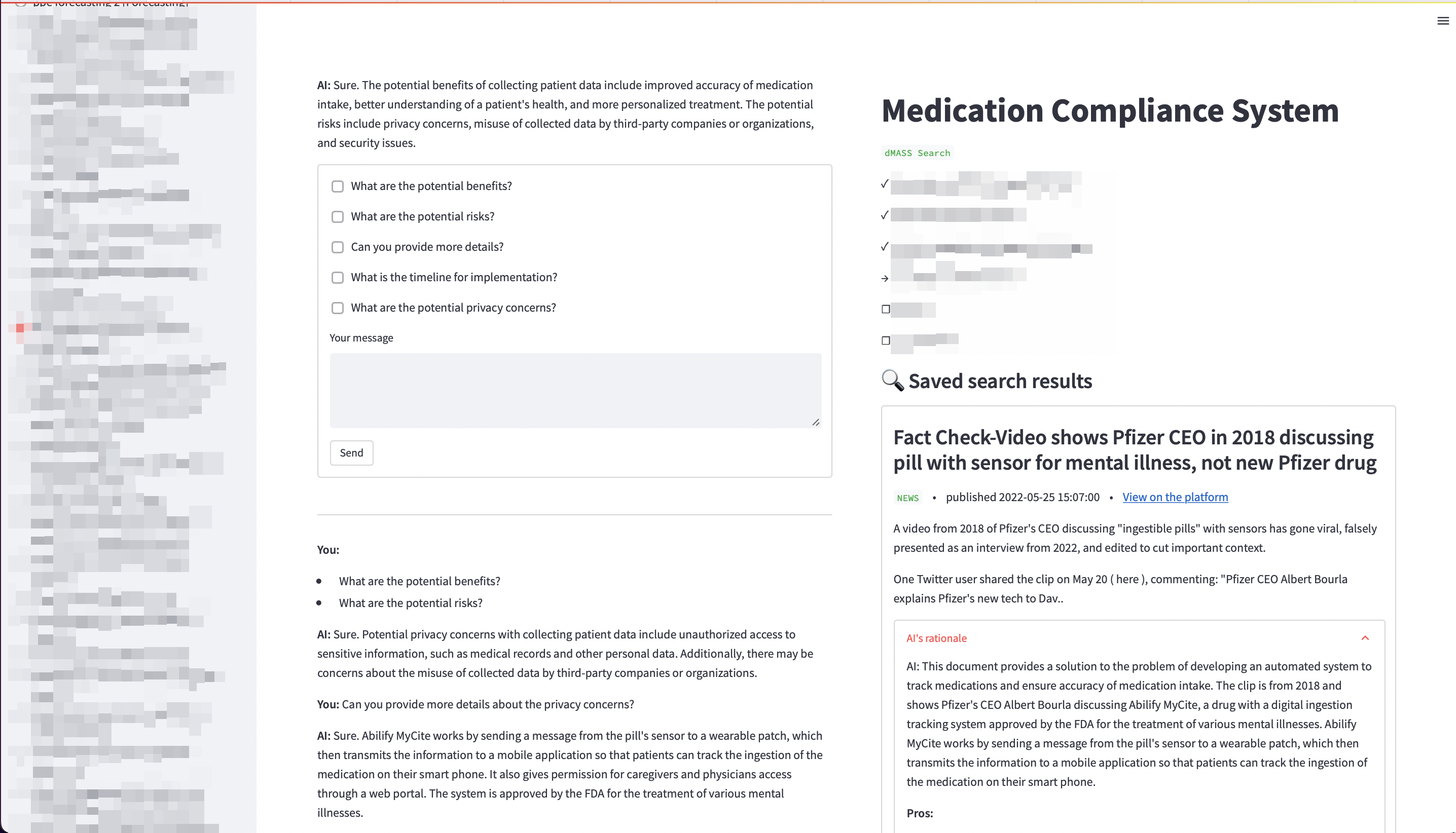 Figure 4: Evolution to LLM-powered semantic search on large private corpora with context-aware relevance ranking
Figure 4: Evolution to LLM-powered semantic search on large private corpora with context-aware relevance ranking
- Advanced Analytics: Developed systems for trend analysis and forecasting
- Created topic modeling and trend analysis tools
- Built LLM-based forecasting capabilities for technology prediction
- Implemented zero-shot innovation detection based on component scores
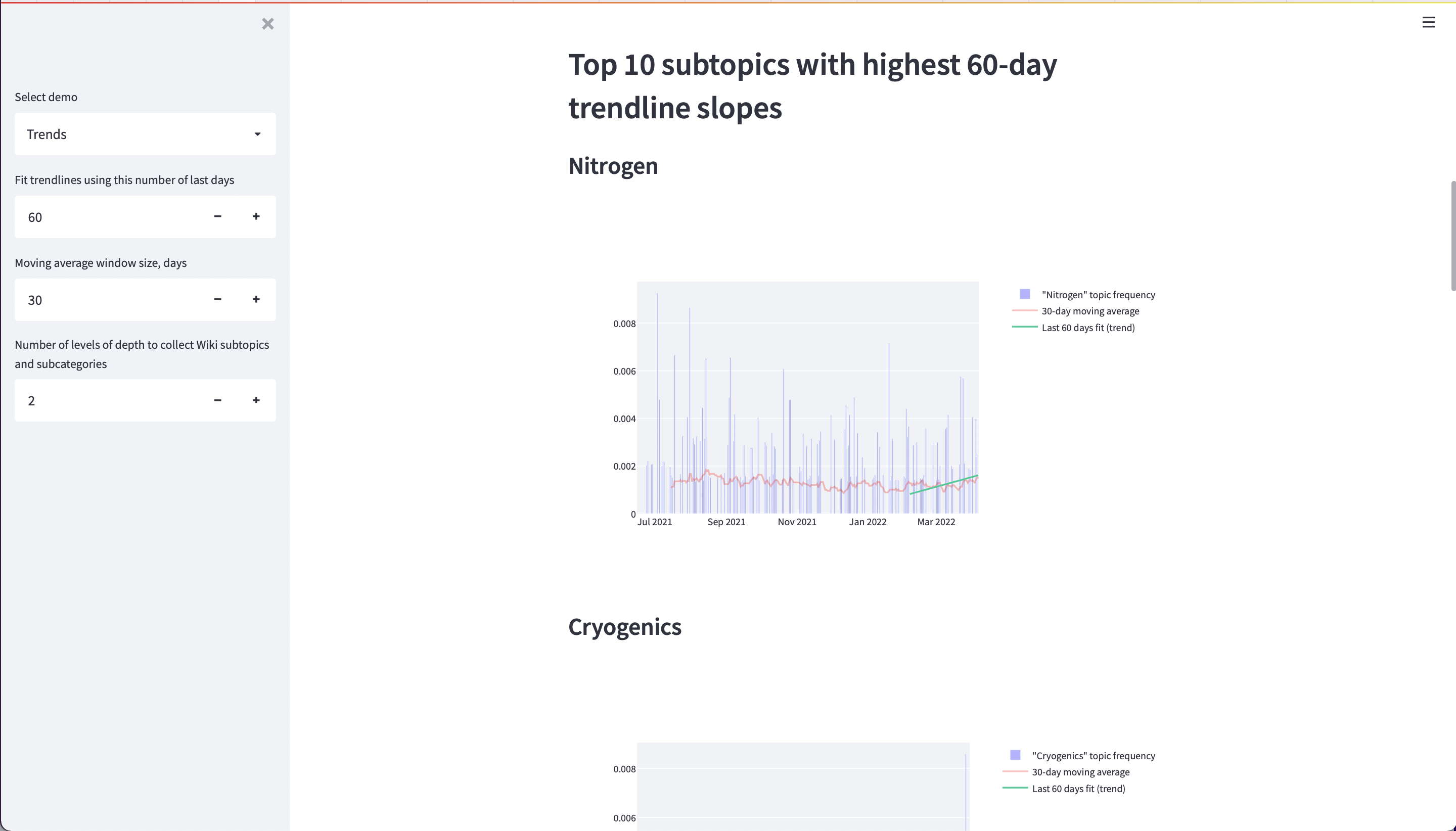 Figure 5: Technology trend analysis based on entities extracted by custom NER models
Figure 5: Technology trend analysis based on entities extracted by custom NER models
Key Technologies
Custom ML Frameworks, Python, PyTorch, Hugging Face (Transformers), spaCy, NLTK, Elasticsearch/OpenSearch, Vector Search (early implementations), GCP, Custom ML Pipelines, Early LLMs (GPT-2 onwards).
Project Highlights
Custom Named Entity Recognition
Figure 6: Custom-trained NER model identifying technologies
Topic Trend Analysis
Figure 7: Visualization of technology trends based on entities extracted by custom NER models
Semantic Search Evolution
From basic semantic search to advanced LLM-powered retrieval:
Figure 8: Early semantic search demo (2019) showing contextual document retrieval
Figure 9: LLM-powered semantic search interface with context-aware relevance ranking
Entity Linking & Knowledge Graph
Our system could identify, extract, and link entities to build a comprehensive knowledge graph:
 Figure 10: Entity recognition interface showing automated identification of key technologies
Figure 10: Entity recognition interface showing automated identification of key technologies
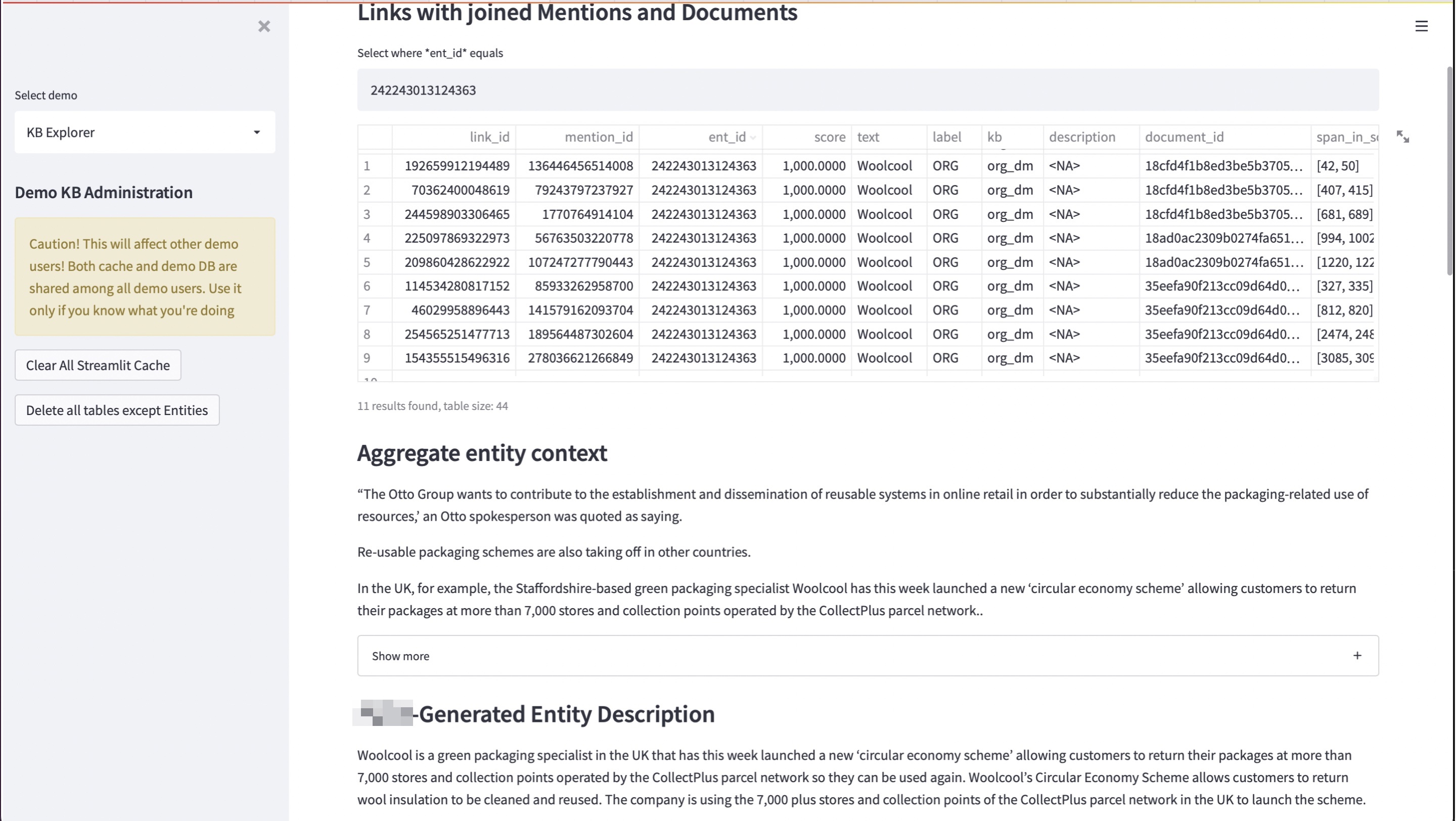 Figure 11: Interactive exploration of newly mined entities and their relationships
Figure 11: Interactive exploration of newly mined entities and their relationships
LLM Applications
Early adoption of language models for various innovation tasks:
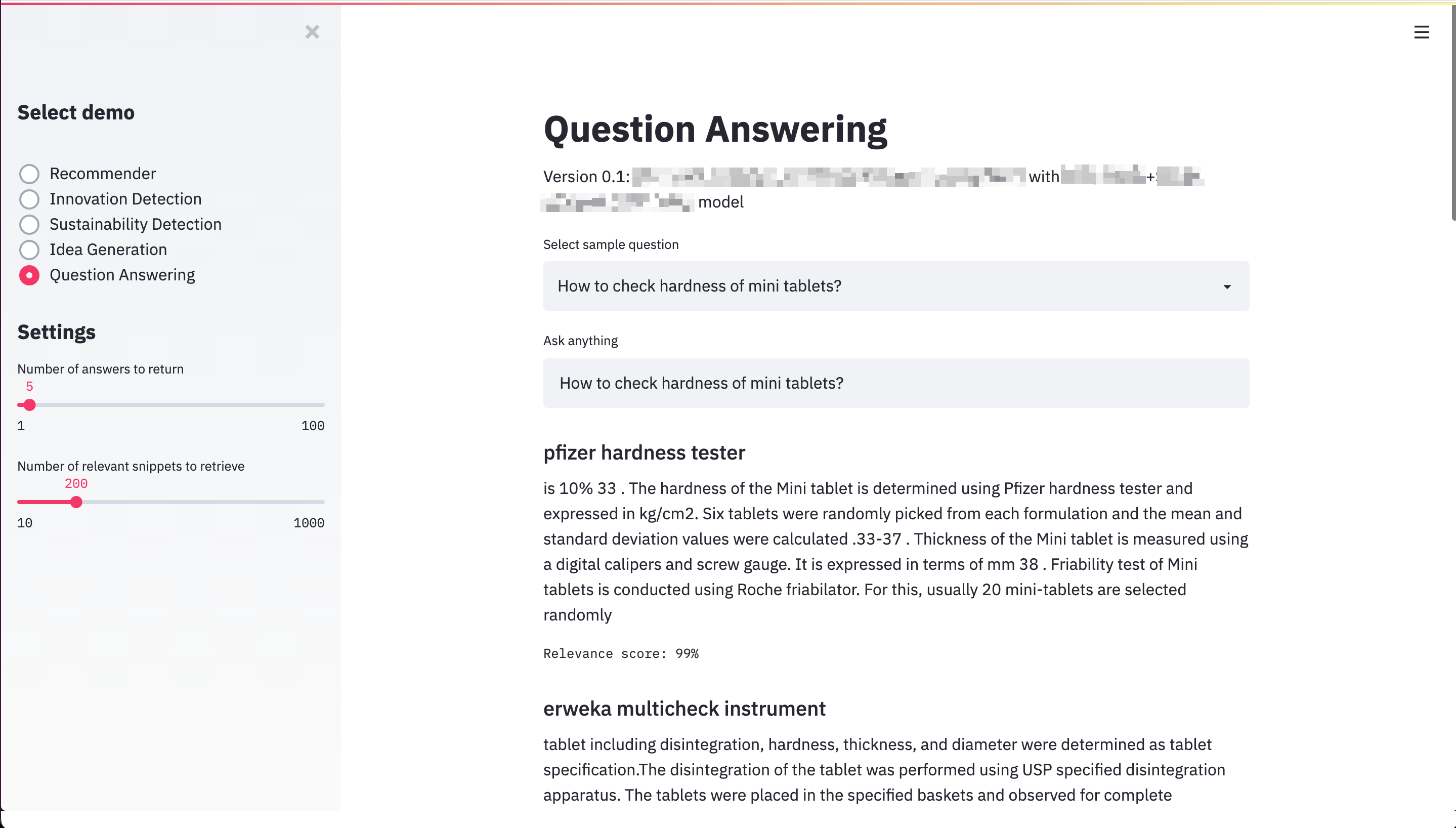 Figure 12: Early Q&A system prototype for innovation research (pre-ChatGPT)
Figure 12: Early Q&A system prototype for innovation research (pre-ChatGPT)
Figure 13: Human-AI collaborative ideation platform for generating novel innovation concepts
 Figure 14: LLM-based forecasting system for predicting technology trajectory
Figure 14: LLM-based forecasting system for predicting technology trajectory
Impact & Scale
Exponentially scaled platform knowledge by approximately 5 orders of magnitude. Implemented core AI search and extraction capabilities that remain in production use. Pioneered practical LLM applications within the organization years before mainstream adoption.
★★★★★ (5.0) “There isn’t any problem that Klim cannot figure out. Simply exceptional. […] If you are looking for an unreasonably productive superstar, rest assured that Klim will exceed your highest expectations.”
Source: Upwork — Client
★★★★★ (5.0) “Klim is outstanding. Full stop.”
Source: Upwork — Client
“Klim is a hyperproductive ML researcher with cutting edge NLP skills. […] successfully delivered several projects ranging from open ended AI research to classifiers, encoders, rerankers, information retrieval systems, benchmarking, and prompt engineering. Klim has a great capacity for working independently, and produces high quality models […] optimized for production use.”
Source: LinkedIn Recommendation — Dennis Kashkin, Former Manager [Link to LinkedIn Profile]