ScanCropper is the production evolution of NerdScan. After building the original open-source prototype, I spent months annotating real scanned album pages, training a custom model specifically for this problem, and turning the workflow into a product that normal people can actually use without touching Python or tuning thresholds.
Production Product
ScanCropper is the maintained, commercial successor to NerdScan.
Overview
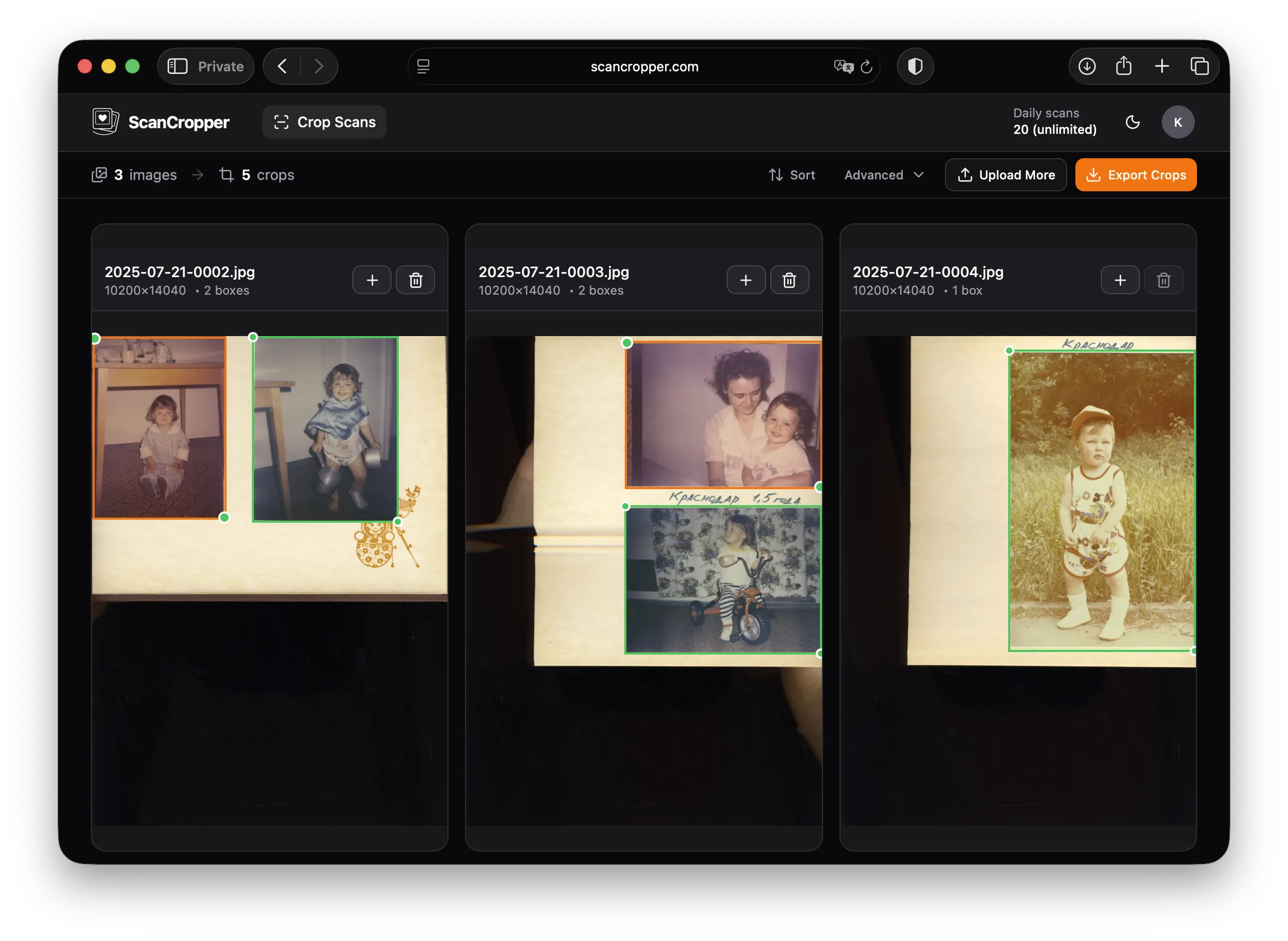
The core challenge is deceptively niche and surprisingly hard: scanned album pages are messy. Photos sit at inconsistent angles, with borders, overlap, dense layouts, aging artifacts, handwriting, and wildly different scan quality. Generic object detection approaches can get part of the way there, but production reliability needs a model and workflow built specifically around this exact problem.
ScanCropper is that specialized system. I built both the model pipeline and the product around the real-world job to be done: upload scans, detect photos, review results, export clean crops, and keep the output organized for tools like Apple Photos or Google Photos.
What Makes It Better Than The Prototype
- Custom model trained specifically on scanned album pages
- Production web workflow instead of a CLI-only tool
- Full-resolution crop export
- Better handling of dense, imperfect, real-world scans
- Cleaner review and export experience for non-technical users
- Maintained as an actual product instead of an experimental repo
Product Design Focus
I did not want this to be “another model demo.” The point was to make the full workflow useful end-to-end: upload, detect, correct if needed, export, and import into a photo library without friction. That meant building around practical details like filenames, chronological organization, and predictable outputs, not just model accuracy in isolation.
Relationship To NerdScan
NerdScan was the original proof of concept. ScanCropper is the commercial successor and the version where ongoing model, product, and UX development happens now.